
CRISalid training data : retour sur trois mois de travail collaboratif
Trois mois d’échanges, d’annotations et de coopération : le projet CRISalid Training Data a réuni 51 participants autour d’un même objectif, entraîner un modèle d’intelligence artificielle pour repérer les doublons de références bibliographiques. Retour sur une démarche collaborative mêlant bibliométrie, IA et science ouverte.
Résumé du projet
Un des objectifs du Consortium CRISalid est d'octroyer une vision globale et en temps réel de la production scientifique des chercheurs issus des établissements membres. Pour cela, un module nommé CRISalid Harvester moissonne automatiquement les données issues de différentes plateformes bibliographiques et les intègre dans une base de données sous la forme d'un graphe de connaissance (module CRISalid Institutionnal Knowledge Graph (IKG)). Toutefois, le fait que ces publications soient moissonnées depuis diverses plateformes peut engendrer des doublons. Une même publication peut apparaître sur HAL, OpenAlex ou ScanR, et parfois plusieurs fois sur une même plateforme, sans identifiant commun ou avec des métadonnées légèrement différentes.
Exemples d'un doublon de publication

Doublon de publication, sans doute déposé deux fois sur HAL, et dont la collecte par OpenAlex a pu accentuer le problème.
Dans ce cas, la même publication a été moissonnée par OpenAlex à la fois depuis Hal et depuis IDEAS/RePEc.
Le consortium s'est engagé dans un chantier visant à consolider la production scientifique des chercheurs et chercheuses issus des établissements membres. Il poursuit ainsi objectif d'octroyer une vision globale et en temps réel de cette dernière en croisant les données issues de différentes plateformes bibliographiques.
Comme expliqué dans un billet précédent, la communauté CRISalid a choisi de s’appuyer sur l’intelligence artificielle pour relever ce défi. L’objectif : entraîner un modèle de langage capable d’identifier automatiquement les doublons non triviaux, c’est-à-dire les publications décrites plusieurs fois sans identifiant commun. Contrairement aux doublons facilement repérables par un identifiant partagé (DOI, identifiant HAL), ces cas exigent une analyse fine.
Le projet CRISalid Training Data a ainsi été lancé pour constituer un corpus d’annotations élaboré par des professionnels des bibliothèques, afin d’adapter le modèle aux spécificités de la production scientifique francophone.
Une deuxième campagne d'annotation
Une première campagne d’annotation a été lancée en septembre 2024, avec pour objectif de tester les outils, affiner la définition des doublons et équivalents. Elle était par ailleurs l'occasion d'identifier les limites du pipeline d'identification des paires de potentiels doublons. Cette phase exploratoire a permis de repérer plusieurs points d’amélioration. Elle a fait l’objet d’un premier article publié sur notre site.
Forte de ces enseignements, la communauté CRISalid a lancé en mai 2025 une deuxième campagne d’annotation à plus grande échelle.
Début mai 2025, un nouveau jeu de données à annoter a été généré. Un nouvel appel à participation a été diffusé sur plusieurs listes de diffusion de professionnels de l'IST et des bibliothèques (notamment BibRecherche, Casuhal et Bibliométrie), invitant les volontaires à rejoindre le projet. Deux webinaires introductifs ont permis de présenter les objectifs et le calendrier de la campagne, ainsi que d’échanger sur la définition des doublons et les cas complexes susceptibles de poser question.
À l’issue de ces présentations, les participants intéressés pouvaient s’inscrire pour recevoir un premier lot de 100 paires de notices à annoter sur la plateforme doccano.
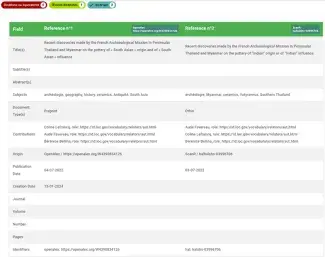
Exemple d’écran de la plateforme doccano, où les participants du projet CRISalid Training Data ont annoté des paires de notices en sélectionnant simplement l’une des étiquettes situées en haut à gauche de l’écran (doublons ou équivalents, œuvres distinctes ou incertains).
Un document collaboratif en ligne était à disposition des participants, chacun pouvait y poser ses questions et obtenir rapidement une réponse des organisateurs. Les échanges étant publics, ils profitaient à toute la communauté. Les échanges réguliers avec et entre annotateurs ont nourri une réflexion collective sur la question du dédoublonnage, problématique récurrente dans le travail des personnels de bibliothèque. Loin de ralentir le processus, ces discussions ont permis de préciser les règles de sélection et, surtout, d’harmoniser les annotations en fonction des pratiques professionnelles.
Au total, 10 000 paires de notices avaient été préparées dans Doccano. La campagne, conçue pour s’adapter au rythme des participants, prévoyait une progression par lots successifs : chacun débutait avec une centaine de paires, puis pouvait en recevoir de nouveau une fois son lot terminé.
Entre le 26 mai et le 26 juin, une première session de travail a permis d’annoter 3821 paires de notices. Elle s’est conclue par un webinaire de point d’étape, consacré à la discussion de cas limites et à l’harmonisation des décisions à prendre face aux situations ambiguës. Durant l’été, une seconde session a permis d’annoter 3518 paires supplémentaires, notamment grâce à l’arrivée de nouveaux annotateurs. Elle s’est achevée le 19 septembre 2025 par un webinaire de clôture qui a permis de dresser le bilan global de la campagne et de recueillir les impressions des participants.
Entre mai et août 2025, 7 339 paires de notices ont été annotées grâce à l’engagement collectif de 51 participants issus de 28 établissements répartis sur l’ensemble du territoire français. Ces résultats témoignent de la réussite d’une mobilisation nationale et de la dynamique collaborative qui a porté la deuxième campagne d’annotation, rassemblant des contributeurs aux profils variés autour d’un même objectif commun. Les graphiques suivants en rendent compte, illustrant la diversité des participants, la représentativité géographique des établissements et la qualité constante du travail réalisé.
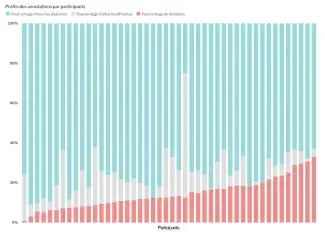
Profils des annotations par participants : répartition des types d’annotations (œuvres distinctes, doublons, informations insuffisantes) pour chaque participant.
Compte tenu de la diversité des lots fournis aux annotateurs, les profils d’annotation par participant montrent une relative homogénéité : la majorité se situe entre 5 et 30 % de doublons, signe d’une compréhension commune des consignes et d’un travail globalement cohérent. Les écarts observés concernent surtout la distinction entre les catégories « œuvres distinctes » et « informations insuffisantes ». Ils peuvent s’expliquer par la difficulté à trancher certains cas et par une application variable de la consigne prévoyant de classer « distinct » en cas de doute. A notre sens, ces différences restent limitées et traduisent avant tout la complexité des situations rencontrées plutôt qu’un manque d’harmonisation.
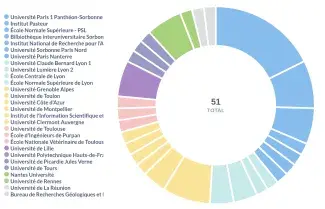
Répartition des 51 participants par établissement : 28 institutions représentées sur l’ensemble du territoire français.
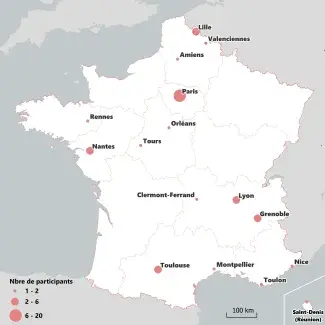
Carte de la distribution des annotateurs en France, agrégés aux centres urbains les plus proches
La répartition des participants par établissement met en lumière la diversité des structures représentées : 28 au total, couvrant l’ensemble du territoire français, dont une majorité extérieure au consortium. Si les pôles parisiens et lyonnais apparaissent logiquement plus fournis, on observe également une participation significative de nombreuses universités — notamment Grenoble, Nantes, Toulouse, Clermont ou La Réunion — avec parfois plusieurs participants par structure.
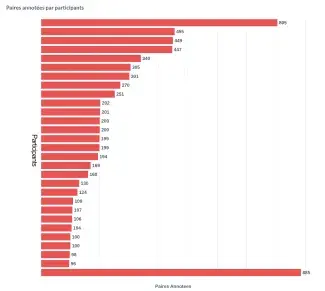

Nombre de paires annotées par participant : volume d’annotations réalisé selon le niveau d’implication des contributeurs.
Enfin les statistiques sur le nombre de paires annotées par participants révèlent trois profils d’engagement : un groupe de tête particulièrement investi, ayant annoté quatre lots ou plus (+ de 400 paires) ; un second groupe ayant contribué à un ou deux lots (soit 100 à 200 paires) ; et un ensemble de participants plus occasionnels. Quelle que soit l’ampleur de leur participation, chaque contribution a été précieuse et a permis d’enrichir la base d’annotations.
Au-delà des chiffres, ces résultats reflètent une aventure profondément collective. En mobilisant les compétences de nombreux professionnels de l’information scientifique et technique, la communauté a démontré toute la valeur de l’expertise de ses membre dans la création de jeux de données fiables et pertinents. Leur connaissance fine des métadonnées, des processus d'alimentation, de curation et des spécificités des plateformes bibliographiques a joué un rôle essentiel dans la qualité des annotations produites.
Les retours des participants lors de la réunion de clôture ont été particulièrement positifs. Tous ont salué la richesse de l’expérience, la qualité des échanges et la dynamique collective née au fil du projet.
Le consortium adresse ses remerciements les plus chaleureux à l’ensemble des participants pour leur engagement, leur rigueur et leurs précieux retours d’expérience.
(Ré)Entraîner un modèle avec les données
Plusieurs approches sont envisageables pour adapter un grand modèle de langage à la détection de doublons bibliographiques. Face à la complexité de la tâche, nous avons choisi d’opter pour le fine tuning d’un modèle de langage existant. Le fine-tuning consiste à réentraîner partiellement un modèle déjà pré-entraîné, en l’exposant à des exemples spécifiques pour qu’il s’adapte à une tâche précise. Le fine-tuning présente plusieurs avantages : il permet d’obtenir des résultats plus cohérents et mieux adaptés aux particularités de notre corpus, tout en restant beaucoup plus léger que l’entraînement complet d’un nouveau modèle. Il requiert également moins de données annotées et de ressources de calcul, et évite le recours à des modèles généralistes très volumineux, souvent surdimensionnés pour ce type de tâche spécialisée.
Plutôt que de réentraîner l’ensemble du modèle, nous utilisons actuellement la méthode LoRA (Low-Rank Adaptation), qui permet d’ajuster uniquement une petite partie des paramètres. Concrètement, cela revient à ajouter des couches sur le modèle existant, sans toucher à sa structure principale. Cela réduit considérablement le coût d’entraînement tout en conservant de bonnes performances. Nous testons des modèles autour des dix milliards de paramètres, ce qui reste bien plus léger que les très grands modèles utilisés au quotidien dans les interfaces généralistes.
Pour l'instant, les résultats sont encourageants. Le modèle parvient à produire des réponses cohérentes et à repérer des doublons non triviaux. Toutefois, la précision reste insuffisante pour un usage opérationnel. Plusieurs pistes d’amélioration sont à l’étude, notamment autour du choix de modèle et de l’ajustement du paramétrage de l'entraînement (ampleur des modifications apportées, nombre de passages sur les données). Ce travail s’inscrit dans un processus itératif : il faut tester, évaluer, réajuster, avec pour objectif une amélioration progressive des performances.
La suite
Le projet progresse et se prépare à entrer dans sa phase de mise en œuvre. Une fois le modèle opérationnel, nous pourrons travailler à son intégration dans l'écosystème des outils CRISalid. L’intelligence artificielle interviendra alors pour analyser les paires de notices repérées comme doublons potentiels et déterminer si elles correspondent effectivement à une même référence. Si c'est le cas, elles seront fusionnées dans le graphe de connaissance avec conservation d'une trace de cette fusion. Les chercheurs et chercheuses disposeront de l’interface Sovisu+ pour visualiser ces regroupements de publications et, en cas d'erreur, procéder à une défusion manuelle.
Pour rester informé(e) sur l'avancement du projet, n'hésitez pas à consulter régulièrement notre site web ou à vous abonner à la liste de diffusion CRISalid. Nous présenterons notre travail et les résultats dès que le système sera opérationnel.
Un grand merci à toutes les personnes qui ont participé à cette deuxième campagne d'annotation ! Grâce à vous, nous disposons d’une base solide pour avancer sur les prochaine étapes du projet.